The Moat for AI
Originally posted here. These are my personal opinions. If you want to add to the discussion, we welcome PRs to this website here.
Before we get started: Hi! My name is GTKlondike, and these are my opinions as a cybersecurity consultant. While experts from the AI Village provided input, I will always welcome open discussion so that we can come to a better understanding of LLM security together. If you’d like to continue this conversation, you can reach me on Twitter at @GTKlondike. And checkout my YouTube channel, Netsec Explained, for more advanced security topics.
This past week, OWASP kicked-off their OWASP Top 10 for Large Language Model (LLM) Applications project. I’m happy that LLM security is being taken seriously and feel fortunate to have joined the kick-off and Slack for this project.
As part of our conversations, there’s been a bit of debate around what’s considered a vulnerability and what’s considered a feature of how LLMs operate. So I figured now would be a good time to take a stab at building a high-level threat model to suss out these differences and contribute to a greater understanding of LLMs in a security context. I’d also like for this post to act as a starting point for anyone interested in building or deploying their own LLM applications.
Finally, we’ll use this definition of a vulnerability moving forward:
Vulnerability: A weakness in an information system, system security procedures, internal controls, or implementation that could be exploited or triggered by a threat source.
Like all good threat models, we’re going to start with a data flow diagram (DFD). This will give us an idea of what a hypothetical application would look like, and where the associated trust boundaries should be. To keep things general, we’re going to be using a level 0 DFD. In the figure below, there’s only a few elements and their associated trust boundaries:
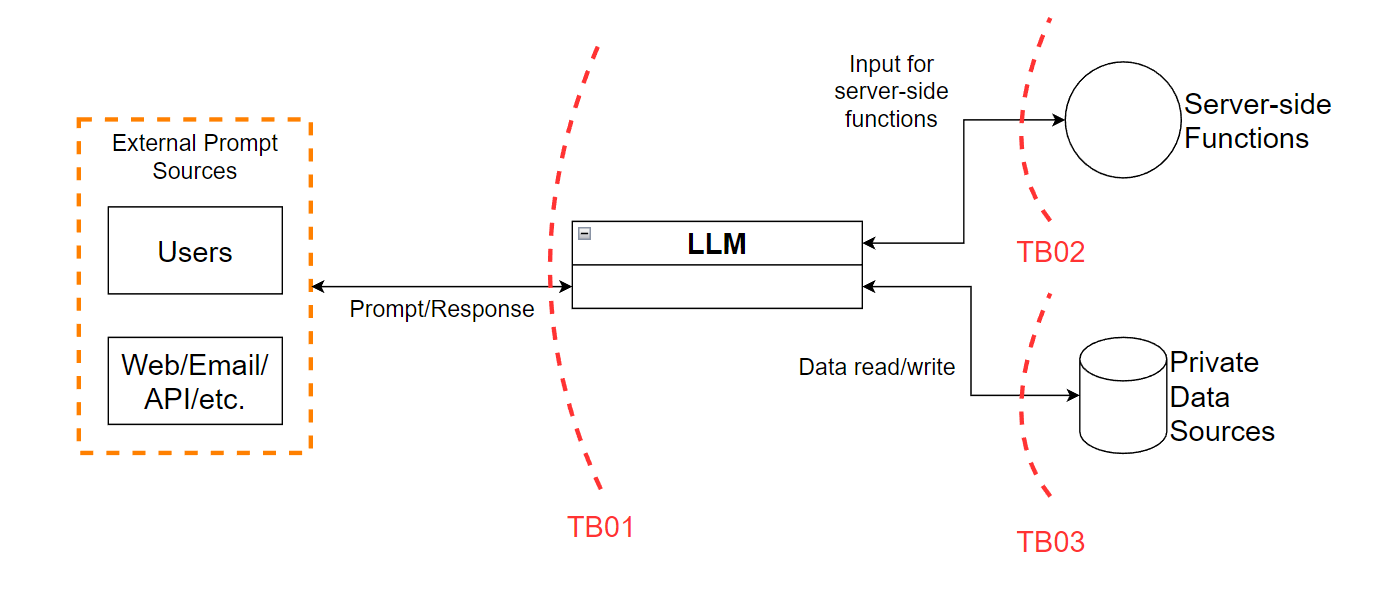
Figure 1 - Level 0 data flow diagram (DFD)
Trust boundary TB01 is between the external endpoints and the LLM itself. In a traditional application, this would be considered the “opportunities for injection”, where an attacker could submit malicious code to manipulate an application. However, LLMs are unique in that we should not only consider the input from users as untrusted, but the output of LLMs as untrusted. The reasoning is that users and external sources could convince the LLM to modify its output in user-controlled ways. This also forces TB01 to be a two-way trust boundary. Not only can the user modify the input, but the output can be modified to attack users. For example, returning a XSS payload back to the user but outside of a code block that would have prevented arbitrary execution.
TB02 and TB03 MUST be considered when building applications around LLMs!
Proper controls along TB02 would mitigate the impact of an LLM passing input directly into an exec(); function or modifying the presentation of a XSS payload being passed back to the user. Likewise, proper controls along TB03 would mitigate the ability for either the LLM or an external user to gain access to sensitive data stores since, by nature, the LLMs themselves do not adhere to authorization controls internally.
We’re also going to introduce a few assumptions we have about the hypothetical application. This is standard practice in more rigorous threat modeling exercises so we’re going to do that here as well:
Cool! Now that we have our DFD and assumptions written out, now we can start with the actual threat enumeration piece. This tends to be the most time-consuming piece of the exercise so do not mistake this as an exhaustive list.
If you’re not familiar, STRIDE is a standard framework in threat modeling exercises. Each letter in the name corresponds to a specific threat category. This STRIDE is incredibly useful in identifying strengths and weaknesses in a system. They are as follows:
When doing this exercise, I find it helpful to take each trust boundary and create tables for the elements communicating across that trust boundary. Typically, I include three tables: left side element, right side element, and communication channel itself. However, since this is a high-level threat model to get us started, two tables will be enough.
For each table we’ll have a column listing out each category of STRIDE as our labels, then a strengths column and a weaknesses column. From there, we’ll go down each category and list out possible vulnerabilities or strengths that would prevent a vulnerability in that category. So let’s take a look at each trust boundary.
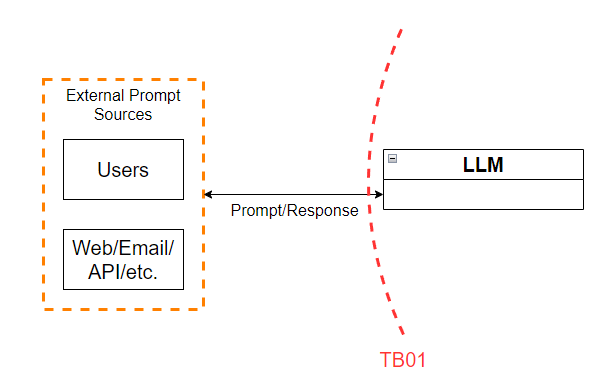
Figure 2 - Trust boundary TB01
This trust boundary lies between the users and external entities such as websites or email, and the LLM itself. As mentioned in the DFD section, TB01 should be considered a two-way trust boundary. For that reason, we’ll list out the weaknesses in controls regarding traffic from external entities as well as traffic from the LLM itself back to users.
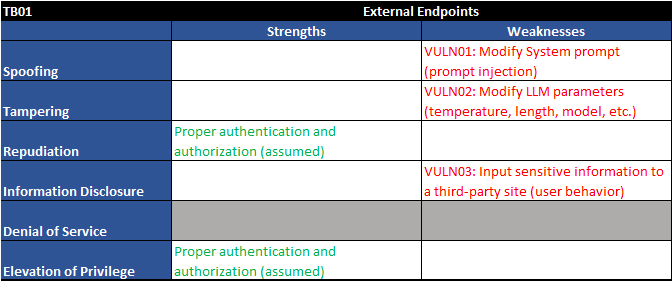
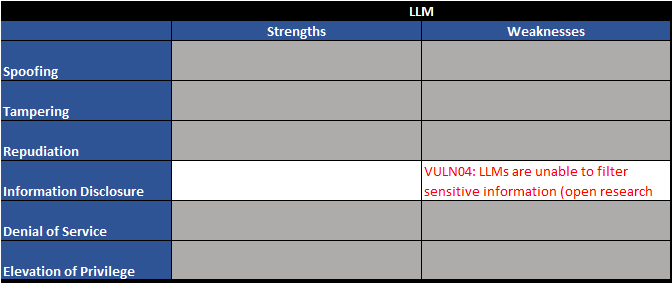
Figure 3 - Trust boundary TB01 - STRIDE table
As shown above, we have four vulnerabilities right off the bat:
| Vuln ID | Description | Examples |
| VULN01 | Modify System prompt (prompt injection) | Users can modify the system-level prompt restrictions to "jailbreak" the LLM and overwrite previous controls in place |
| VULN02 | Modify LLM parameters (temperature, length, model, etc.) | Users can modify API parameters as input to the LLM such as temperature, number of tokens returned, and model being used. |
| VULN03 | Input sensitive information to a third-party site (user behavior) | Users may knowingly or unknowingly submit private information such as HIPAA details or trade secrets into LLMs. |
| VULN04 | LLMs are unable to filter sensitive information (open research area) | LLMs are not able to hide sensitive information. Anything presented to an LLM can be retrieved by a user. This is an open area of research. |
Table 1 - Trust boundary TB01 - vulnerability list
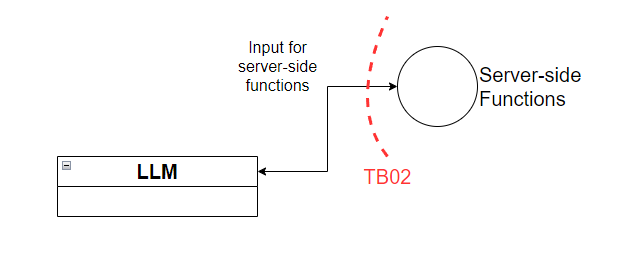
Figure 4 - Trust boundary TB02
This trust boundary lies between the LLM and backend functions or services. For example, a LLM may request a back-end function to perform some action based on a prompt it’s received. In the case of TB02, we want to make sure we’re not passing unfiltered requests from the LLM to the back-end functions. Just like we should put both client-side and server-side controls in modern web applications, we should also put client-side and server-side controls in LLM applications.
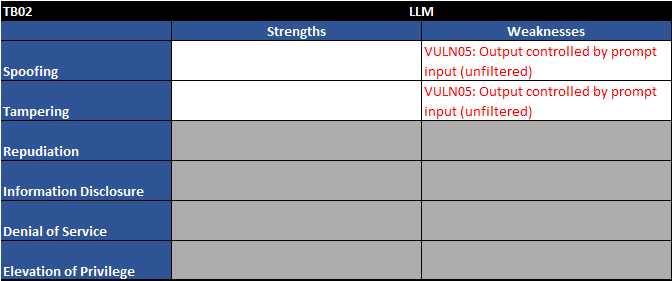
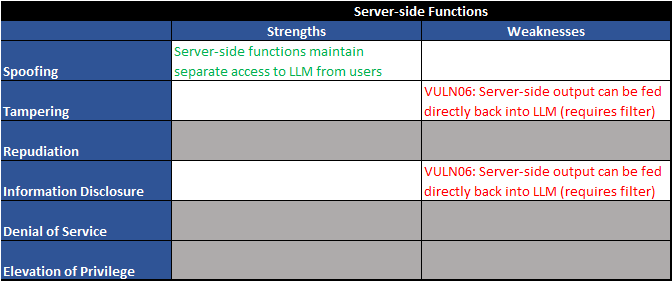
Figure 5 - Trust boundary TB02 - STRIDE table
Two major vulnerabilities stick out to us:
| Vuln ID | Description | Examples |
| VULN05 | Output controlled by prompt input (unfiltered) | LLM output can be controlled by users and external entities. Unfiltered acceptance of LLM output could lead to unintended code execution. |
| VULN06 | Server-side output can be fed directly back into LLM (requires filter) | Unrestricted input to server-side functions can result in sensitive information disclosure or server-side request forgery (SSRF). Server-side controls would mitigate this impact. |
Table 2 - Trust boundary TB02 - vulnerability list
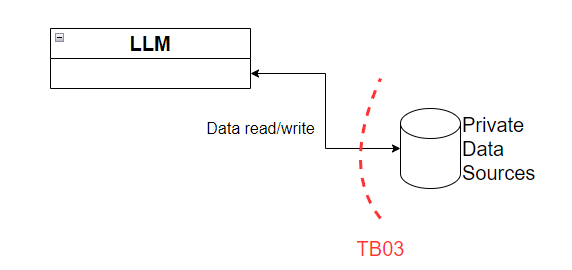
Figure 6 - Trust boundary TB03
This is the last trust boundary we’re going to take a look at, TB03. This trust boundary lies between the LLM and any private data stores one might have. For example, reference documentation, internal websites, private databases, etc. In here, we’ll want to ensure that we are applying necessary authorization controls and the principle of least privilege outside of the LLM since LLMs themselves cannot do this on their own.
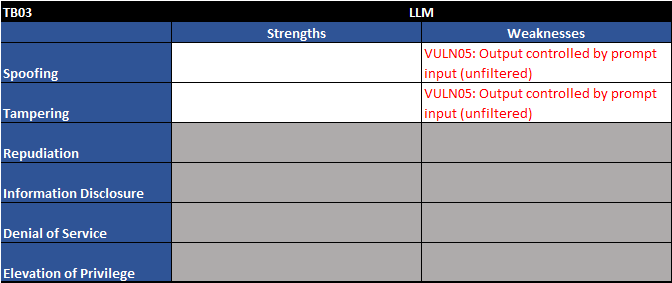
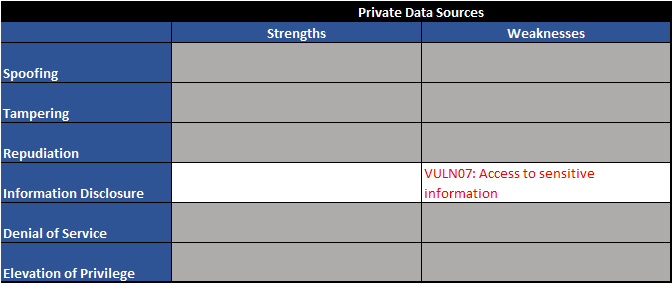
Figure 7 - Trust boundary TB03 - STRIDE table
As one would expect, we see one familiar vulnerability along with a new one on the private data sources element:
| Vuln ID | Description | Examples |
| VULN05 | Output controlled by prompt input (unfiltered) | LLM output can be controlled by users and external entities. Unfiltered acceptance of LLM output could lead to unintended code execution. |
| VULN07 | Access to sensitive information | LLMs have no concept of authorization or confidentiality. Unrestricted access to private data stores would allow users to retrieve sensitive information. |
Table 3 - Trust boundary TB03 - vulnerability table
What about hallucinations?
If you’ve followed AI in the news lately, I’m sure you’ve come across the term “hallucinations” to describe when LLMs completely fabricate facts as part of their output. Many would consider this to be a vulnerability, but I’d push back on that. When you look at what exactly LLMs do to generate their output, they use previous tokens to predict the statistically most likely token to come next. You’re already familiar with this approach if you’ve ever used the predictive text feature in your smartphone: “Finish this sentence with the most likely answer, ‘the cat sat on the _____’.” Therefore, this is not a bug, it’s a feature and as security professionals we should plan around this known limitation.
One last thing to say here is that the term, “hallucination” is being disputed in AI circles. Hallucinations are part of a human psychological experience, when in this case the LLMs are instead just confidently making things up. Another proposed term is “confabulation”.
Personally, I just say they make things up. Public communication is hard enough, don’t let words get in the way of the message.
What about training data poisoning, bias, or hate speech?
This is a bit of a personal thought: Yes, data poisoning, bias, and hate speech is a problem in the development and fine-tuning of the model itself. At the same time, this application-level threat model assumes that the LLM is complete already.
With that, for data poisoning to occur, likely 1 of 2 things would have to happen:
I think to accept this as a risk worthy of our list, we should locate a recent CVE or real-world example of this occurring outside of a purely academic space. I’m not saying it isn’t possible, I’m just not convinced it’s common enough to warrant being on the list.
To round out this exercise, here are some high-level recommendations to get us started. As mentioned at the beginning, this is not an exhaustive list.
Not a lot we can do directly, but we can mitigate the downstream effects. Ensure the LLM isn’t trained on non-public or confidential data. Additionally, treat all LLM output as untrusted and enforce necessary restrictions to data or actions the LLM requests.
Limit the API attack surface that is exposed to external prompt sources (users, website content, email bodies, etc.). As always, treat external input as untrusted and apply filtering where appropriate.
This is a user behavior problem but we can educate users via statements presented during the signup process and through clear, consistent notifications every time a user connects to the LLM.
Do not train LLMs on sensitive data that all users should not have access to. Additionally, do not rely on LLMs to enforce authorization controls to data sources. Instead, apply those controls to the data sources themselves.
Treat all LLM output as untrusted and apply appropriate restrictions prior to using results as input to additional functions. This will mitigate the impact a maliciously crafted prompt could have on functions and services within the internal environment.
Perform appropriate filtering on server-side function output. If the LLM stores the output for future training data, ensure sensitive information is sanitized prior to retraining. If the LLM returns function output (in any form) back to a user, ensure sensitive information is removed prior to returning such information.
Treate access from the LLM as though it were a typical user. Enforce standard authentication/authorization controls prior to data access. LLMs have no way to protect sensitive information from unauthorized users, so the controls must be placed here.
Altogether, this exercise has been pretty fruitful. We have 7 high-level vulnerabilities to address. Again, this is just to get us started by walking through the process of formally threat modeling an LLM application. Here’s the full table of the vulnerabilities we’ve identified so far, in the order we that found them above:
| Vuln ID | Description | Examples |
| VULN01 | Modify System prompt (prompt injection) | Users can modify the system-level prompt restrictions to "jailbreak" the LLM and overwrite previous controls in place. |
| VULN02 | Modify LLM parameters (temperature, length, model, etc.) | Users can modify API parameters as input to the LLM such as temperature, number of tokens returned, and model being used. |
| VULN03 | Input sensitive information to a third-party site (user behavior) | Users may knowingly or unknowingly submit private information such as HIPAA details or trade secrets into LLMs. |
| VULN04 | LLMs are unable to filter sensitive information (open research area) | LLMs are not able to hide sensitive information. Anything presented to an LLM can be retrieved by a user. This is an open area of research. |
| VULN05 | Output controlled by prompt input (unfiltered) | LLM output can be controlled by users and external entities. Unfiltered acceptance of LLM output could lead to unintended code execution. |
| VULN06 | Server-side output can be fed directly back into LLM (requires filter) | Unrestricted input to server-side functions can result in sensitive information disclosure or SSRF. Server-side controls would mitigate this impact. |
| VULN07 | Access to sensitive information | LLMs have no concept of authorization or confidentiality. Unrestricted access to private data stores would allow users to retrieve sensitive information. |
Table 4 - Full vulnerability list
And a list of recommendations to help mitigate each vulnerability:
| REC ID | Recommendations |
| REC01 | Not a lot we can do directly, but we can mitigate the downstream effects. Ensure the LLM isn't trained on non-public or confidential data. Additionally, treat all LLM output as untrusted and enforce necessary restrictions to data or actions the LLM requests. |
| REC02 | Limit the API attack surface that is exposed to external prompt sources (users, website content, email bodies, etc.). As always, treat external input as untrusted and apply filtering where appropriate. |
| REC03 | This is a user behavior problem but we can educate users via statements presented during the signup process and through clear, consistent notifications every time a user connects to the LLM. |
| REC04 | Do not train LLMs on sensitive data that all users should not have access to. Additionally, do not rely on LLMs to enforce authorization controls to data sources. Instead, apply those controls to the data sources themselves. |
| REC05 | Treat all LLM output as untrusted and apply appropriate restrictions prior to using results as input to additional functions. This will mitigate the impact a maliciously crafted prompt could have on functions and services within the internal environment. |
| REC06 | Perform appropriate filtering on server-side function output. If the LLM stores the output for future training data, ensure sensitive information is sanitized prior to retraining. If the LLM returns function output (in any form) back to a user, ensure sensitive information is removed prior to returning such information. |
| REC07 | Treat access from the LLM as though it were a typical user. Enforce standard authentication/authorization controls prior to data access. LLMs have no way to protect sensitive information from unauthorized users, so the controls must be placed here. |
Table 5 - Full recommendations list
That’s a wrap! I hope this exercise has been helpful and that it’s empowered you to be more security conscious when it comes to building and deploying LLM powered applications.
Originally posted here. These are my personal opinions. If you want to add to the discussion, we welcome PRs to this website here.
Generative Red Team History
Threat Modeling LLM Applications Before we get started: Hi! My name is GTKlondike, and these are my opinions as a cybersecurity consultant. While experts fr...
Largest annual hacker convention to host thousands to find bugs in large language models built by Anthropic, Google, Hugging Face, NVIDIA, OpenAI, and Stabil...
The Spherical Cow of Machine Learning Security
Prompt Detective Announcement
Disclaimer: This does not reflect the AIV as a whole, these are my opinions and this was my response.
AI and ML is already being used to identify job candidates, screen resumes, assess worker productivity and even help tag candidates for firing. Can the inter...
The Red Team Village and the AI Village will host a panel from different industry experts to discuss the use of artificial intelligence and machine learning ...
Automate Detection with Machine Learning
A few useful things to know about AI Red Teams
Automate Detection with Machine Learning
Generative Art at AI Village DEF CON 30
Welcome to the second post in the AI Village’s adversarial machine learning series. This one will cover the greedy fast methods that are most commonly used. ...
Originally posted on Medium - follow @sarajayneterp and like her article there
Welcome to AI Village’s series on adversarial examples. This will focus on image classification attacks as they are simpler to work with and this series is m...