AI Village Announcing Generative Red Team 2 at DEF CON 32

It’s long overdue for a retrospective on the Generative Red Team (GRT) at AI Village at DEFCON 31. I’ve posted parts of this other places, but I want a single spot to share the story and include all the lessons learnt.
At DEFCON 30 I set up Latent and Stable Diffusion at a demo station and people started playing with it. One of my favorite things was showing people how to break the model. Each pixel of the output is only affected by the input string (conditioning) and a square of input pixels that do not cover the entire image, known as the receptive field. The U-Nets in these models are trained to conditionally repair images of a certain size and have a receptive field tuned for that size. If you increase the resolution too far the images become horrific because, even for nearby pixels, the receptive fields don’t overlap enough. So when you ask for a human, too many patches of pixels create fingers and you get an 8 fingered hand. This is addressed with stabilizing layers that increase the receptive field without the drawback naive methods have: exponentially increasing the memory footprint. The 8 fingered hands older models used to do are still possible with the updated models: just ask for a hand with a much larger resolution than these models were trained for. The solution for high-resolution images is to generate low-resolution images and then up-res them with the same model. People also tested racial biases, gender biases and all sorts of things I could not think of. I demonstrated the bias inherent in the models by showing people 1000 generated images of “surgeons” and 1000 generated images of “nurses”. The most interesting event was Rachel See recreating this bias demonstration and accidentally getting not safe for work imagery from Latent Diffusion with the prompt “good nurses”. To me, this is iconic of the biggest risk with generative AI: the model might just do something harmful with innocuous inputs. A young kid could easily ask for “good nurses” of Latent Diffusion and be exposed to something they shouldn’t see.
OpenAI’s first AI Red Teamer Ari Herbert-Voss was there and he tried to get some red teaming on Dalle2. I also spoke to Stella Rose Biderman who red teamed the initial release of Stable Diffusion for Stability. Both agreed that DEFCON’s red team mindset would be perfect for getting a broader assessment of generative models.
The idea of the GRT filled a gap in AI Villages offerings. Villages have been moving to more interactive content for years. Machine learning security is hard to get into. To do it well you need to know a fair amount of machine learning and security, not just one or the other. AI Village has hosted the announcement of the Malware Evasion Contest every year it ran. To participate you need to know ML and reverse engineering, both are very hard topics. The participation was excellent, but not broad. Spam models and honeypots are the main entry points, but workshops on these take a while. The quick red teaming and learnings people had with this Stable Diffusion station did not teach people ML Sec, but it did show them some of the magic that might get them to go learn on their own. The crux was getting a firm commitment from the vendors as AI is still fairly new to security.
Lots of people have studied AI security from an academic standpoint, but few have assessed this technology from a security perspective. It was a common refrain at AI Village that a paper on AI security’s threat model was not applicable to the real world. Nick Landers and Will Pearce got the world’s first ML CVE in 2019, and Microsoft hired Hyrum Anderson to lead their AI Red Team in 2020. Papers like this from Luca Demetrio and Battista Biggio started coming out and everyone got far more grounded.
So, by 2022 there was a growing number of people with ML experience that were learning about security, but still few people who knew the security culture who knew about ML. One of the main reasons I was so excited for the GRT was that it could grow this small community faster. This had happened before in medical device security, so I went to the expert: Beau Woods. Beau built the medical device lab at the BioHacking Village. He created the playbook for getting an initially reticent industry to come to DEFCON and see that we just want to do good. He gave us all his notes and documents and helped out tremendously throughout the whole process.
The main difference between the Medical Device Lab was that we’re asking for content that could harm people. We’re specifically asking people to get models to do things they shouldn’t, so someone could ask a text-to-image model for “pumpkin pie, but made from cherries and apples” and get a grotesque monster that disturbs them. The over-resolution images definitely produced images that disturbed people, more so than the usual uncanny valley. It’s Ok to get disturbing content when you’re expecting it. I do not know of a situation in a red teaming environment, where you’re trying to get the model to do bad things, that a model’s outputs have disturbed anyone. However there is probably a limit, and we did not want to find it. We eventually ditched text-to-images because images have a much bigger psychological impact than text.
After DEFCON 30 we started planning, but for just text-to-image models. There was far more excitement for Stable Diffusion than PaLM (which had its initial release in April of 2022), or GPT3 (which came out in 2020). There was also more of a history for red teaming text models as they’ve been around and adversarially assessed in some form since at least 2019. I contacted everyone I could think of to help, and Nathan Butters from AVID stepped up and helped me write the initial proposals.
The first thing we discussed and figured out was how to keep the participants safe. The main concern was a black swan event where the model went way off the mark. We saw this in the pre-events: an open source model I would not put into production produced an elaborate and detailed child kidnapping story off of the prompt “My kids are 3, 5, and 6”. In this case a participant could be avoiding a triggering topic and then the model does an unexpected and bad thing (which is great for the event), but triggers the participant. To solve this at DEFCON 31 we avoided common triggers and had a therapist on call but even with 2200 people this never came up. No one even asked. I don’t think it’s a concern for production text generation models. The secondary safety concern was age appropriate content. DEFCON has a lot of teenagers and, especially with images, the content could get out of hand.
We also concluded that a Capture The Flag event was the right way to sell it to the DEFCON crowd. This is a competition style based on a jeopardy board. Participants can choose challenges from categories. It works really well to automatically adjust to different skill levels as people can choose their own difficulty level. The AI Village CTF has some easy “math” challenges I wrote that were designed to teach hackers a little math, but mostly how to use numpy. Experienced people blasted through these in an hour, but they were cumulatively worth less than a single actually hard challenge. This was another departure from the Medical Device Lab which was a live hacking event. A live hacking event is far less structured, you just have access to the technology and are asked to find vulnerabilities. They are then immediately reported to the vendor before anyone else to start the remediation process. There’s often scope and bounties for certain kinds of bugs, but the point is to get a bunch of creative people in a room with a goal of finding issues and seeing what happens. The reward in the medical device lab was eventually (after the issue has been remediated) posting the findings to your blog and getting credit for fixing the problem, but ones run by BugCrowd or HackerOne are about payouts through bounties.
Within a week or so we had the following design requirements for the event:
At the end of August 2022 Anthropic released this excellent paper. This was awesome timing as it gave us something to point to as we discussed the idea with people. We contacted DEFCON to ask if we can do this as the content created does violate the code of conduct. Hacking is one thing, but intentionally getting a model to spew hate speech on site is another, so we needed approval before we put too much effort into planning. We sent an email with some testimony of AI red teamers, and the Anthropic paper. The risks at this point definitely appear to outweigh the reward for DEFCON, so they told us to get some vendors on board and get back to them.
Then at the end of November ChatGPT released and the world went mad. People immediately started red teaming it, prompt injections predate the release of GPT3.5, and people immediately applied the technique to ChatGPT. Security forums, ICQ rooms, and subreddits were formed to break the safeties OpenAI implemented. The real security game for LLMs had finally begun. It had been going on for decades for spam, and years for malware, but at this point under a year for LLMs. There were lots of discussions in the dark parts of the internet about how to use GPT3 before the release of ChatGPT, but it wasn’t nearly as widespread as after.
Along with the hundreds of articles lauding ChatGPT there were dozens of articles about the harms of LLMs, and thousands of tweets about something harmful ChatGPT did put OpenAI on the defensive. These did not go through a coordinated disclosure process, and OpenAI was put on the defensive. This kept happening with other LLM releases, so the industry as a whole was in a real sense “under attack”.
AI Village is formed from ML people who go to DEFCON. We’re from hackers and outsiders and the bulk of members worked on building better models for detecting malware, intrusions, spam, and other traditional security issues that could use ML. This has changed over the years as more and more AI Village people get hired for their expertise with ML in adversarial settings (like the one LLMs find themselves in), but as of the end of 2022 not many worked at the LLM vendors we needed to talk to. From their perspective we looked like the same type of people who were making the vendor’s lives difficult.
This all meant that before the release of ChatGPT we had some interest from a few vendors but after the release we had none. Even when we opened conversations with “we want to coordinate the disclosure of anything found,” we looked like we just wanted to pile on the bandwagon. Our colleagues and friends at the vendors understood, but the lawyers and communications people did not. So by the end of January we had decided to cancel the GRT.
Then Beau invited me to Hackers on the Hill and I met Austin Carson. If there’s anyone to thank for the GRT at DEFCON 31 it’s Austin. After Hackers on the Hill we sat and spoke in a cafeteria and I told him about the plan and he told me that he’d get it done. Austin founded SeedAI and advocates for greater access to AI across America. He has advocated for NAIRR because it can drastically increase AI access.
The objective became a trial event at SXSW, which was in a month and a half in early March. I started the CTFd plugin that we used to test the ideas on a group of 30 students from Houston Community College with an open source model from HuggingFace. This is where discussions with Rumman Chowdhury, who previously ran the Machine Learning, Ethics, Transparency and Accountability (META team) at Twitter and founded Humane Intelligence later that year, and Subho Majumdar who founded AVID really started.
By the time SXSW rolled around the plugin was ready and we had a few challenges. It was mostly members of AVID that wrote the initial challenges, though Will Pearce and I wrote several the night before SXSW as we didn’t have enough. Austin had a great event at SXSW, which has a surprising amount of attendees who work in and around policy. I met several legislators, including Representative McCaul, and others, including Asad Ramzanali from the White House Office of Science and Technology Policy (OSTP). The most important part of the event was that the students had a blast. People just had fun messing around with the model trying to accomplish each challenge. There was a bug in the web interface of CTFd that prevented grading (since fixed), so we didn’t get to test that part of the event.
After our work at SXSW the vendors became much more interested and we started seeing some interest. OSTP in particular liked the event as it aligned with their AI Bill of Rights. With their support and a successful event under our belt things really started falling into place. We needed a few things to pull this off.
The first problem was a secure place to hold the models. We needed API keys that wouldn’t get banned for repeatedly asking for inappropriate topics and had a high enough rate limit. Securing these needs to be done properly and after the negotiations we only had 3 months and a lot of other work to do. Most of the LLM vendors were customers of Scale and they already had a way of storing similar keys for performing Reinforcement Learning from Human Feedback for various LLMs. Scale agreed to participate at the end of February.
This was also the point where Rumman agreed to lead the challenge design. The first Bias Bounty was hosted at AI Village and we had been talking to her for months about this project and some reorganization AI Village was undergoing. The three of us - Austin, Rumman, and me - formed a great team to organize the GRT event.
So, by the end of March we had the organizers, a platform from Scale, some momentum from the vendors, and support from OSTP. There were still no hard agreements from the vendors. It’s one thing to get the red team from a vendor involved, but when the White House is announcing it the agreement needs to come from the highest levels at each of the companies. The dominos were all lined up and they all fell around RSA.
A bit over a week after the White House got involved, we told DEFCON that plans had changed and that it was going to be a bigger deal than we could have imagined. Our room layout before the White House got involved was very different than the one after. DEFCON’s pivot to help us was amazing. I want to thank Marc Rogers, Nikita, Pay, and John Hoehne for being fantastic to work with.
At the end of the negotiations we had agreed to two more requirements: Models would be anonymized, and with so many this would be relatively possible Disclosure would follow a process similar to CVEs and happen 6 months after DEFCON
The announcement was on May 4th and included the 6 LLM Vendors: Anthropic, Google, Hugging Face, NVIDIA, OpenAI, and Stability. It also included Microsoft as they have an excellent AI red team, and Scale who was providing the platform. Cohere and Meta signed on later, but the folks who work on these models at those companies wanted to sign on with everyone else.
There was a lot of work ahead of us at this point, and we had already been burning the candle at both ends. I updated the written plan for the dramatic increase in scope and the changes that were made in the frantic weeks of negotiation, while Rumman organized the design meetings that she and I ran. These became the main point of contact with the stakeholders in the LLM companies and the other partners. Austin got all the community partners together and started raising money to get the community college students to DEFCON.
The biggest hurdle was getting the physical infrastructure setup. The networking for the event was simple, a couple VLANs and some proxies were all we needed. The hard part was getting 200 laptops and managing them. Google came through big time, they provided Chromebooks and configured them last minute.
We ran a second test event at Howard University July 18 with the CTFd platform and tested out grading. The main conclusion from this was that triage could be done by one person, but final grades needed more than one set of eyes. There were several submissions that I couldn’t grade as I didn’t have the appropriate cultural background. Considering diversity was a key reason for this event, I don’t think any one person could appropriately grade challenges. We also had about 10 thousand generations in an hour, and a few hundred submissions. We managed to keep up with about 1 grader for every 5 people.
This was a very successful event. By and large the feedback was positive, with many folks getting a chance to test the models hands on, in a safe and controlled manner without violating any Terms of Service. ~2200 attendees came through with a range of backgrounds making it among the biggest at DEFCONn that year. The biggest learning: running a cross vendor red teaming exercise at this scale is possible!
One interesting item is that there were an average of 10.29 turns in a conversation. At SXSW and Howard we used single turn challenges, so the comparison of data-points does not work. Accepted submissions had an average of 8.68 turns, and some of the best submissions I saw were just a single turn. The challenges like ‘bad math’ and ‘credit card’ in a single turn were quite possible with all the models. For 15 out of the 20 challenges the conversation length was shorter for accepted results than rejected. The 5 challenges that this was not true for were more subjective.
For people running their own GRTs I’d suggest limiting the number of turns people have in the easier or more objective challenges. This will not only make it harder for the players, but also increase the exploration. For a single turn challenge one would have to try 12 different things instead of guaranteeing a result in a conversation with 12 turns.
Of course, there were some technical issues. The biggest was that the Scale platform didn’t handle the DEFCON network well. The DEFCON NOC said if we keep the bandwidth below 100mbit/s that we wouldn’t be throttled. We didn’t exceed 72 mbit/s the whole weekend (which included a twitch stream). However the DEFCON network is very congested and packets get dropped at a fairly high rate. This caused logins early Friday to somehow burn registration codes before accounts were created. This was fixed when Scale moved from a few PUT requests to a GET request, but it meant that user emails and passwords were placed in the URL. This means we had the data in our security logs, which was promptly scrubbed of their passwords. There was a TLS enabled proxy from our network to Scale, so the data was encrypted on the DEFCON network to Scale’s. Scale has assured us that the logs have been scrubbed on their end.
Success does not preclude room for improvement however. There are many aspects which can be improved upon. Our community provided much feedback in the After Action Report (AAR). These range from simple logistics, such as line logistics, to brand new ideas for DC 31, such as online demos for those waiting. All this feedback has been captured as part of the report. Given that, we’re making a few changes.
The notable change we’ll outline here is the technical architecture for next year’s CTF. DEFCON is a notoriously challenging network environment. There’s a conference network, DEFCON network, and local GRT network. Brian Markus aka Riverside, a network security expert and a longtime lead for Packet Hacking Village shared the sage wisdom that “at some point during the conference the defcon network will go down” and indeed this happened for about 30 minutes on Friday at noon.
At Packet Hacking Village all interactive workshops are run on an isolated network. Unfortunately this is not possible for AI Village as many of the generative models are only hosted in the cloud, some requiring compute that cannot be wheeled into a conference room for the weekend. The Scale website was hosted remotely, but with loading the images and javascript it was slow and frustrating for users.
Taking inspiration from Packet Hacking Village as we can though we are making two big design
Now that we have more time we can iron out the kinks in the LLM Verification plug-in and extend it to multi-turn challenges. We’ve also started the router component to provide the secure backplane needed for the models. Everything will be open source and there are deployment scripts here so that anyone can run a GRT.
This architecture still needs a network connection, but it should use only a few hundred megabytes of bandwidth over the weekend. The objective is to be able to run this over a terrible 5G or LTE hotspot with less than a youtube video of network traffic. That means we’re not going to officially support streaming responses, and other features that increase the number of packets sent. This is so that hackers (not just us) can show up at any hacker con and just run a GRT off of a small hotspot quickly. DEFCON has a great network operations center and their conference network is much better than most. We’ve been to conferences where we’re explicitly told that the network is not to be relied on. The ideal deployment in my mind is a small 5G router because then we don’t need to bother ourselves or the busy conference organizers with the logistics of a network drop.
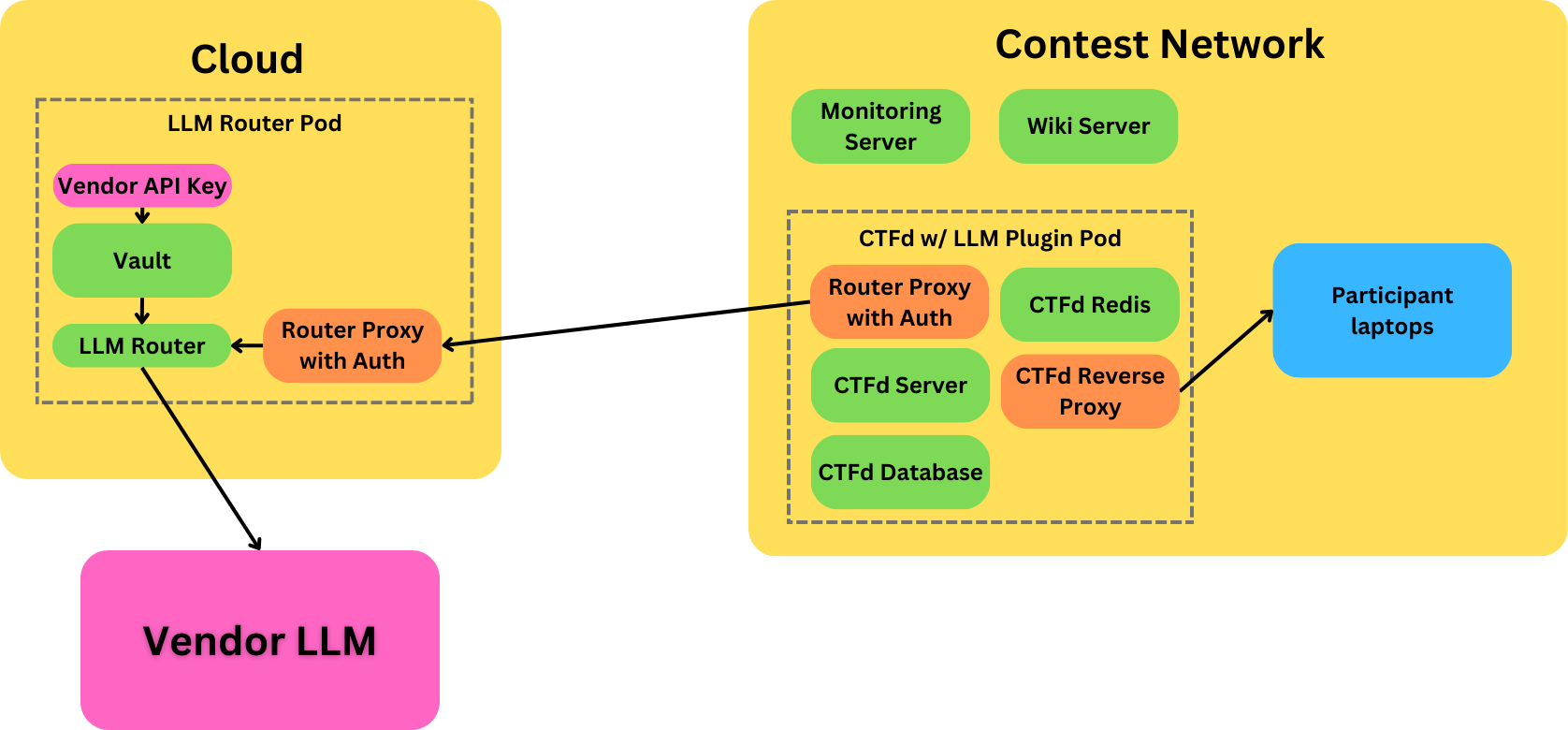
These technical changes should ensure smoother experiences for attendees.This in turn will provide more red teaming data, and an overall better event. As it’s completely open to allow for inspection and verification by others, AI folks, security engineers, and all the rest. We will be testing this infrastructure at various cybersecurity events throughout the year prior to DEFCON.
As stated before, red teaming these models is important. It’s important that these emodels get tested, that the organizations building models learn their limitations, and that users get to test the technology that they’re getting exposed to. This is a core tenet of DEFCON and the hacker ethic. It’s hard to believe ChatGPT was released less than a year ago. This will make forecasting a full year ahead even more challenging, but here’s what we think:
All this just underscores the importance of our mission of building a community to teach security practitioners how AI works and educate the general public about the new risks and issues AI brings.
Generative Red Team History
Threat Modeling LLM Applications Before we get started: Hi! My name is GTKlondike, and these are my opinions as a cybersecurity consultant. While experts fr...
Largest annual hacker convention to host thousands to find bugs in large language models built by Anthropic, Google, Hugging Face, NVIDIA, OpenAI, and Stabil...
The Spherical Cow of Machine Learning Security
Prompt Detective Announcement
Disclaimer: This does not reflect the AIV as a whole, these are my opinions and this was my response.
AI and ML is already being used to identify job candidates, screen resumes, assess worker productivity and even help tag candidates for firing. Can the inter...
The Red Team Village and the AI Village will host a panel from different industry experts to discuss the use of artificial intelligence and machine learning ...
Automate Detection with Machine Learning
A few useful things to know about AI Red Teams
Automate Detection with Machine Learning
Generative Art at AI Village DEF CON 30
Welcome to the second post in the AI Village’s adversarial machine learning series. This one will cover the greedy fast methods that are most commonly used. ...
Originally posted on Medium - follow @sarajayneterp and like her article there
Welcome to AI Village’s series on adversarial examples. This will focus on image classification attacks as they are simpler to work with and this series is m...