AI Cyber League

People have forgotten how old AI security is, and have relearnt the basics of defense over the last 4 years. The oldest public report on a vulnerability or flaw in a machine learning or AI model is from 2004. It’s bayesian poisoning which is the classic “shove extra information into the content to confuse the model”. The algorithm (Naive Bayes Classifier) is permanently vulnerable to this and the solution is to move to a different model type. However, even if the model doesn’t have a similar flaw a “secure” model is no different from a perfect model that’s correct 100% of the time. That doesn’t exist and will never exist. It’s a goal, one that we strive to achieve. We may get 99.999% of the way there, but if we don’t design for the 0.001% of the time that model fails and maintain it, the results are undesirable. The ban of Fable by the US government is at least in part due to a jailbreak, which is inevitable. The real test of security is how fast Anthropic patches jailbreaks with and without disclosure and how effective those patches are.
We measured ourselves on the speed we could detect and respond to new types of attacks and mitigate the potential damage caused.
Pedram Keyani
This quote sums up the main game of AI security. Pedram was one of the founding members of the site integrity team at Facebook in 2007, and now works at OpenAI. The first wave of AI security engineers were the spam teams at social media and providers of spam reduction tools like Google, Facebook, and Sophos. Machine learning models took the security industry by storm in the late 2010s. Microsoft’s Malware Challenge and the preponderance of VirusTotal integrations enabled startups to build effective anti-virus products for cheap. Other aspects of the Security Operations Center (SOC) that had large volumes of data were also addressed by AI.
AI gets used in security contexts when there’s a resource (LLM, email, computers) that has a fairly large traffic volume and a potential for abuse. If the traffic is small enough, we can use authentication to control access to that resource to trusted people. If there’s no potential for abuse, security isn’t needed. If abuse is catastrophic then a more expensive solution is needed. Spam, malware, prompt injections are all abuse, but the majority of the use of these is valid traffic. The vast majority of GPT traffic is valid requests by customers who are mad if the request gets blocked. Very few are using prompt injections to bypass guardrails that are mostly meant to enforce Terms of Service.
A website login relies on the developer to have correctly set up the site, and for your session to be encrypted correctly. There are several single points of failure that must work to ensure your session is not stolen. The modern development stack has millions of lines of code that execute for even simple sites. Bugs in the code will always exist at this level of complexity, making a vulnerability inevitable. One or more of these single points of failure will fail. However AI is different because we know the attackers can essentially walk around our fence we put up. We know how they will do it, they will probe the inputs until they find one that works. Anyone who tells you they can secure this without a maintenance caveat is lying. Relying on AI to provide security is a recipe for a bad time. It can and should be treated as an integral part of a security solution, not a complete solution. The objective is to build the fence and then maintain it. Over time the fence grows longer and harder to get around and the cost asymmetry imposed by defenders on attackers becomes the security model.
There are nearly universal engineering principles for how to achieve this, but details vary wildly.
Universal Principals
There’s 2 metrics to track from a high level perspective, time-to-bypass and time-to-respond. Bypass here means: the attackers who want to abuse your resource have found a reliable way to do so. This can be a jailbreak that works well enough, or a spam technique that you do not catch. What is the expected time for your attackers to find a bypass? How fast can you respond?
Layered defenses are essential to both aspects.
Time-to-Bypass
Your objective is to build a model that satisfies the customer’s requirements, and has the longest time-to-bypass. When building the model and testing it in production you have to be aware of the attacker’s psychology and economics as well as how your model fails. An adversarial attack is outside of the capabilities of most attackers. This requires a fair amount of expertise and there’s often cheaper alternatives.
The best model is often the most accurate. Robustness against adversarial attacks built off of known points (the ones you’re probably already training on) can be a distraction.
Time-to-Respond
The first part of responding to a bypass is finding out that it’s happened. This is remarkably difficult and mature teams spend the majority of their time on this problem. Usually there’s a dashboard with some metrics and error prediction pipelines to help maintain acceptable error rates. Mature companies actually spend far more on detection than model development. Because attackers are highly innovative and will eventually exploit errors, you must be prepared to see an attack and react immediately. Your initial response doesn’t have to be a robust block; utilizing simple blocklists can stem the tide of malicious traffic. From there, your objective is to minimize the time from realizing you need to retrain the model to the final deployment. The

Competition
The AI Cyber League (AICL) is designed to bridge industry and academia, teaching the dynamic, cat-and-mouse nature of MLSec. Because static datasets cannot capture the constant innovation of attackers, this competition operates as a “purple team” environment. You will be defending and attacking models in miniature, providing each other with the stream of novel attacks that drive innovation in AI defenses.
We are currently running a small scale competition in conjunction with Signapore Management University and HTX.
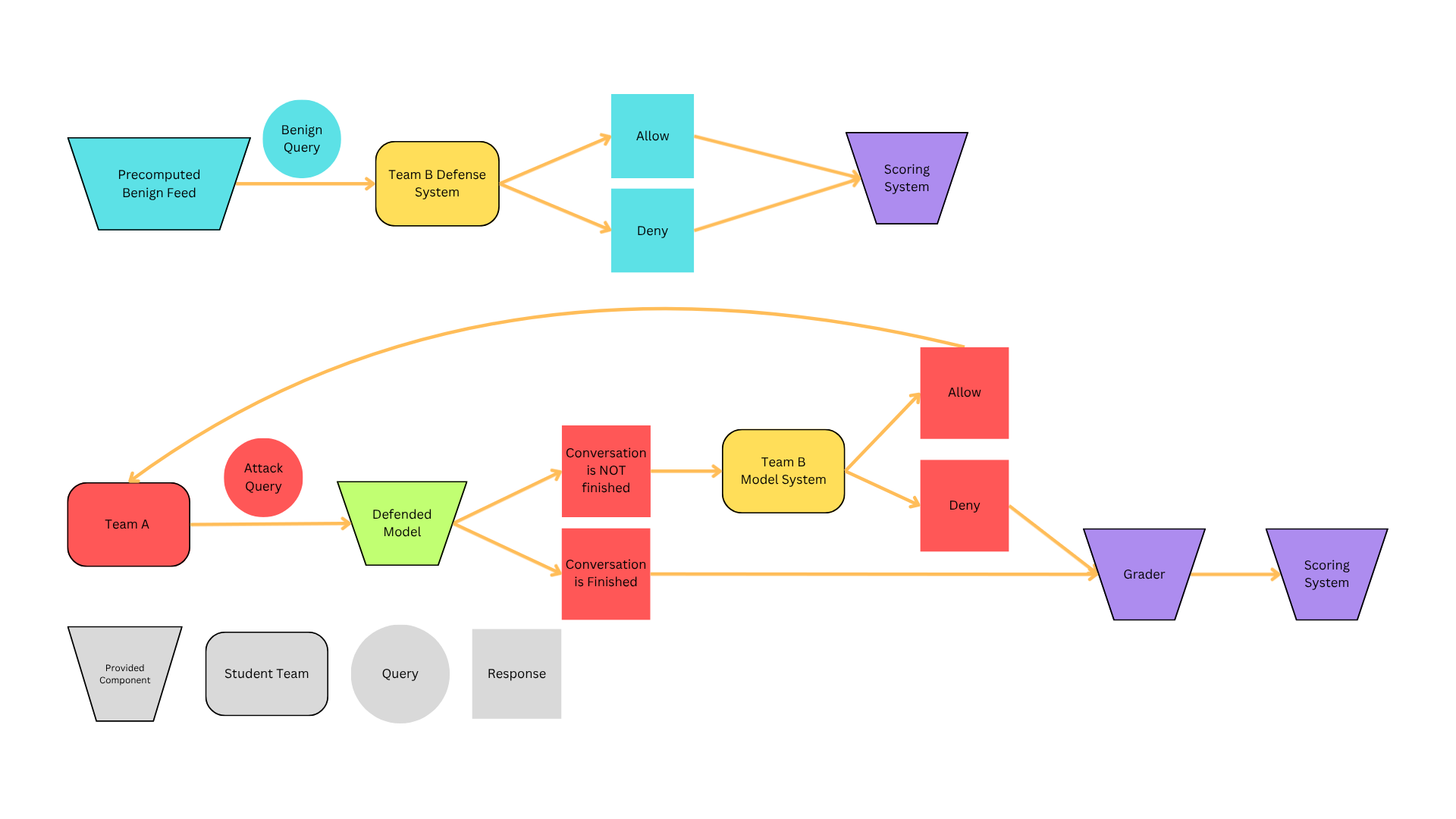
The Defender’s Task: Building the Moderator Service
Your Blue Team is responsible for building and maintaining a backend moderation service that adheres to the provided OpenAPI specification. The game engine will hit your POST /moderate endpoint with a post request containing a chronological log of ChatMessage objects. These are going to be a mix of benign feed from us, and malicious queries from the other teams. To make this realistic the benign data be the vast majority of the data.
- True Positives: You must successfully identify and block the successful violations of the rules sent by the opposing Red Teams (return block: true).
- True Negatives: You must allow the benign feed to pass through unimpeded (return block: false).
- The Penalty: If your defenses are too aggressive and you start blocking the benign feed, your false positive rate spikes.
The rules are particular to the workshop and you have 5000 benign conversations to get your defense started. As each conversation is approximately 12 steps, the 5000 conversations will be streamed to you as about 60000 queries. Over 2 hours, that’s 500 queries per minute.
You will not be able to tell the difference between your opponent and the
The Attacker’s Task: Chatting Through the Opponent
Your Red Team is responsible for actively breaking the defensive Moderator Services built by other teams.
You will not have direct access to their source code or backend models. Instead, you will “chat” with their model by sending crafted payloads directly to our endpoint labeled with the target team’s model. The central chatbot is the same. Your goal is to confuse the central chat bot into violating the rules in a way that also bypasses the opponent’s chat model.
- Crafting Bypasses: You must generate novel attacks, such as jailbreaks, to confuse the chat model into misbehaving while also crafted in such a way that the opponent allows a malicious request through (forcing their service to return block: false on a payload that should be blocked).
- Iterative Probing: Just like real-world search engine optimization or spam techniques, you will try different methods until one succeeds.
- Exploiting Out-of-Distribution Data: Models are unpredictable when faced with data they haven’t seen before. Your goal is to generate inputs that the opposing team’s model was never trained to handle.
We manage the session history, so follow the guide for the API pattern expected to hold a conversation. This is to prevent you from editing the main chat bot’s defense.