Generative Art
Generative Art at AI Village DEF CON 30

Today, models that appear to generate novel outputs conditioned on text are becoming the mainstay of popular culture. New groups of users are starting to adopt generative architectures and bring new modes (experiential, creative) of interacting with large models. The understanding of model performance is becoming increasingly qualitative and subjective, as is evident in the latest benchmarks for text-to-image models.
We would like to give a platform to the artists and those building large foundation models to come together, and begin to form a shared understanding of each other’s approaches.
The State of Generative Art
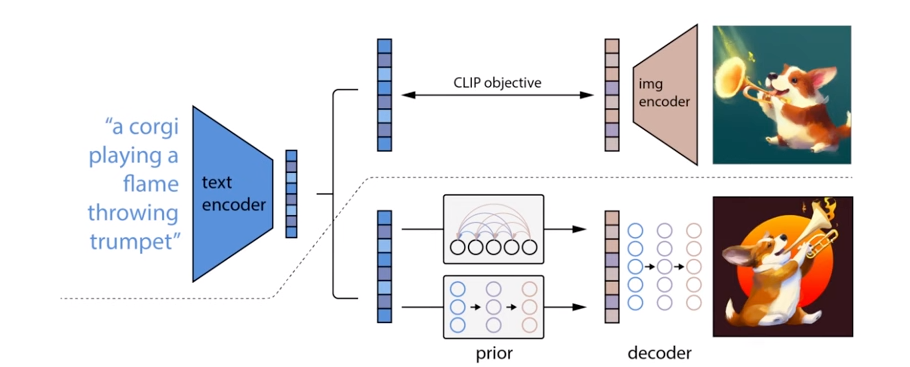
Source: https://www.youtube.com/watch?v=xqDeAz0U-R4&t=101s
Image generation based on text prompt is no longer stuff of science fiction - you can experience it for yourself! Elaborate notebooks and libraries that were necessary for style transfer are now as simple to reproduce and get never-before-seen images with the correct prompt, e.g. “a painting of a river in the impressionist style of Claude Monet” (insert your favorite style / painter) is all that’s needed to get a grid of custom-baked Twitter thread.
Today, new frontiers like photorealism, scaling output resolution, generating images from complex scene descriptions consistent with our understanding of prepositions in the real world, and sample-efficiency have become the areas where large models compete with one another. Given the nature of the models, the comparisons between their outputs had to acquire a subjective quality.
Implications for Responsible Machine Learning
This focus on prompt selection in a multimodal setting introduces a new mode of interaction with a generative model - instead of careful tweaking of hyperparameters, elaborate architecture development, and bruteforce iteration through the optimizable spaces - artists develop a set of shared guidelines of the best prompts to use, begin relying on their intuitions. More and more diverse groups of users are now able to bring their context and recondite knowledge of the landscape of human creations (likely seen in the training data, and present in the latent space), combine styles, objects, and concepts to condition generation in ways that achieve their creative intent. In a way, the breadth of the datasets that the models expose to are now allowing the use of obscure references, and produce renderings of their use at a rate and level of sophistication that many can begin to see as impressive and even original.
What can this purposeful exploration of the latent space of the model mean for those of us working at the intersection of models and their undesirable behavior?
- the ever-growing examples of model outputs, their viral reposting on social media can serve as a way of incentivizing discovery of the “interesting” properties of what is possible to generate using model weights
- these examples of interest can further be allowed to focus on areas that would be difficult to pinpoint through bruteforce example generation, and difficult to direct for engineers building them, unless those subject to negative outcomes based on the output bring their perspective and express their anxieties about unintended memorization as evocative prompts - what does "
" worker in ” return? can a collection of these unintended outputs be used to retrain / fine-tune the model?
Art Day
Ongoing exhibits
- interactive station + volunteer to guide those passing by through the generation process using a common public model
- printouts and QR codes pointing to the papers that have advanced the generative art forward
Workshops
- interactive walk through a tutorial in order to understand how your text turns into images GPU compute to generate interesting artifacts to be provided through Google Collaboratory and other cloud notebook sponsors (several laptops will be provided on-site for the duration of the workshop to those who require them)
Meet & Greet
(attendance limited)
- following the day of workshops, we invite you to join us for an evening at the wonderful Nerd Bar in the heart of Las Vegas - meet with the generative artists, those collecting their work, as well as the workshop attendees who make it to the very end and will be able to see their work displayed at the event
Call for artists!
If you would like your work to be featured during the event or have interest in participating in the workshops or socials, please fill out the following form: https://forms.gle/7gHS76gaEtVtinWz5
References
- OpenAI CLIP - text-to-image og
- DALL·E 2 can create original, realistic images and art from a text description. It can combine concepts, attributes, and styles.
- Imagen: Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
- On the Opportunities and Risks of Foundation Models